
This post is for both programmers and business users of Hadoop. I will not go too much into the technical detail of a Hadoop cluster. The focus will be on the business value and limitations of the technology.
Introduction
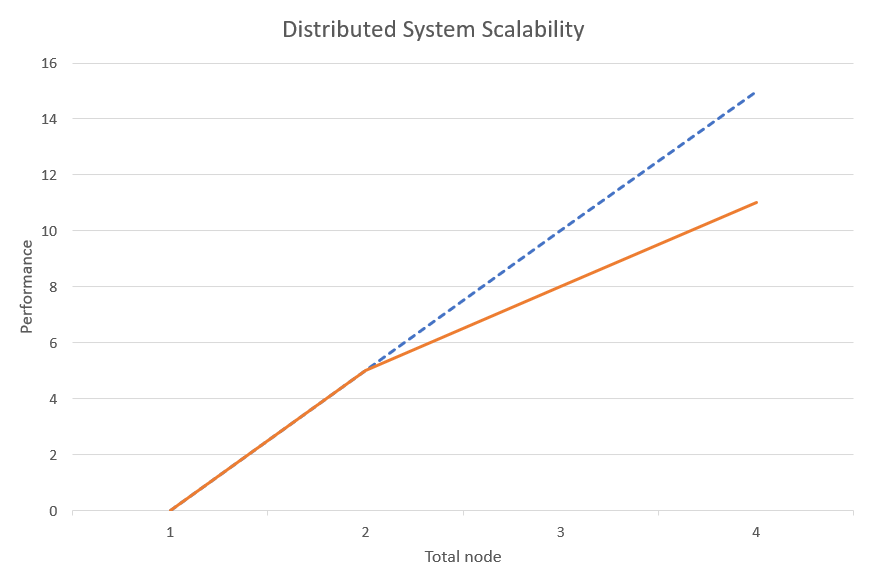
Hadoop is powerful, but distributed computing is not new. Why is Hadoop so popular nowadays, especially for Big Data? The answer lies in its ability to maintain a linear system performance boost with respect to the number of nodes in the cluster. Early distributed computing suffers diminishing returns as the number of nodes grows.
What is Hadoop?
Hadoop is an open source framework written in Java that allows for distributed computing and storage across large cluster of commodity computers with simple programming models. You can store and process hundreds Petabyte of data with Hadoop.
At its core, Hadoop is consists of 2 components: MapReduce for distributed computation, and HDFS (Hadoop Distributed File System) for distributed storage.
MapReduce Framework
Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.
MapReduce job read the input from HDFS and split it into independent chunks of data that are then submitted to more than one or more node(s) to process in parallel. It does this by grouping input data into key, value pair of data. Records with the same key are sent to the same node for processing.
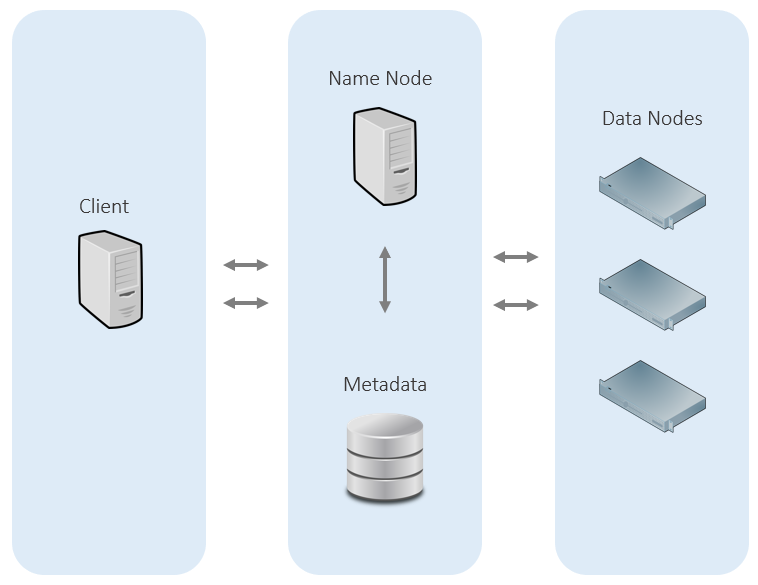
HDFS
HDFS is a File System for Hadoop. It is designed for distributed computing. It can run on commodity hardware and can store hundreds of Petabytes of data. Storing data across clusters enables the system to run parallel processes simultaneously using separate physical hardware.
HDFS is designed to be fault-tolerant by replicating data across its clusters. It is resilient against physical hardware failure and data corruption.
Managing data in HDFS is familiar for most Unix/Linux users. Data is organized into folders, tree-like structure. All files in the HDFS cluster appear in HDFS as a single folder/drive from the client’s perspective. There is no need to know the physical location of the file. Basic operations such as the listing of files, download, upload, rename, etc. are all supported with familiar command line.
HDFS Architecture
Apache Hive
Hive is open source data warehouse software that simplifies reading, writing, and managing large datasets residing in distributed storage using SQL.
You can use Hive to perform data loading and retrieval of tabular data with SQL-like commands. Hive uses its own language named HQL (Hive Query Language). The structure is very similar with SQL commands with some differences. For example, you can store JSON in Hive and query it as such “select address.postalcode from person“.
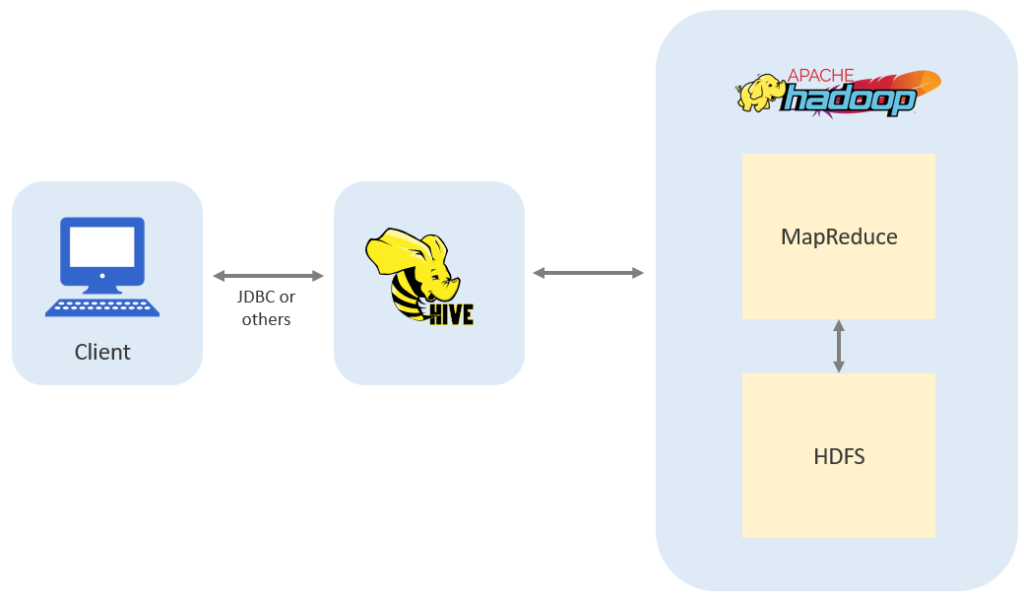
Overall process
- The process starts with writing instructions for Hive in HQL. The client will send the HQL to Hive Server.
- Hive server translates the HQL into MapReduce job and submits it to the job tracker in the name server. We will learn more about MapReduce job in the following section.
- Job tracker will procure and coordinate data nodes to execute the MapReduce job.
- Data nodes execute the MapReduce job and store the output in HDFS.
- Hive reads the output, does the necessary transformation, and returns the result back to the client.
Support for JDBC
Hive supports JDBC driver. You can use tools traditionally used for SQL database on Hive. E.g. SQL Developer, DBeaver, Java Spring JDBC, etc.
The advantage is it simplifies development by allowing developers to use tools they already know, in the language they use frequently.
Use Case
By now you should have realized the structure of Hadoop is highly optimized for read operation. Write operation is much slower because the system has to read data first, check for duplicates, write data in a node, and then replicate it in another node. Because of this Hive is meant for storing and retrieval of large datasets for OLAP processing, online analytics.
| Hive | Classical Database |
|---|---|
| OLAP | OLTP |
| Schema on Read | Schema on Write |
| Scale to 100s Petabytes of data | Maximum 10 Terabytes |
| Supports compression with different file format | Compression is handled by the database |
| Not a relational database | Relational Database |
Schema on Read
Different from the classical database, Hive performs Schema on Read, meaning it only validates tabular data against schema structure when reading. Data can be inserted by copying the file into HDFS.
Not a relational database
It is important to understand that Hive processes tabular data, not relational data. Hive does not support foreign keys constraint, and it is not wise to join tables in Hive. Tables should be de-normalized into few tables as it is slow to join tables.
Final thoughts
You have now learned the difference between Hive and classical databases.
To sum it up, classical database is designed for flexibility, you can use it for both OLAP and OLTP operations depending on the table design, but it’s not capable for big data processing with its limited computing and storage capability. Hive, on the other hand, is designed for big data because it’s optimized to read and process data from a cluster of commodity hardware. Hive will not replace the classical databases anytime soon.
Would you like to learn more about Hadoop, MapReduce, or something else? Let me know your thoughts below.

